

智能体的规模化部署必须扎根于坚实的数据土壤。想要将技术能力转化为实际业务价值,技术领导者需聚焦四项核心工作:推动高价值工作流“智能体化”、升级数据架构、提升数据质量,并重塑组织运营模式。
根基不牢,地动山摇。智能体亦是如此,越来越多的企业已深切体会到这一点。全球近三分之二的企业已试水智能体,但真正实现规模化部署并创造可观价值的不足一成1。症结多半在于数据基础薄弱。八成企业将数据短板视为智能体规模化的障碍(见图1)。《麦肯锡讲全球企业数字化(第二版)》(Rewired)研究指出,补齐数据短板是打牢AI能力根基的关键一环,也是区分企业能否依靠AI创造成果的分水岭。
过去,企业尚能在一定程度上应对数据碎片化、孤岛化的问题,但进入规模化阶段,这些隐患便无处遁形。更麻烦的是,治理标准不统一,企业很难在保留数据语境的同时,严格落实权限管控、数据溯源与可审计性要求。
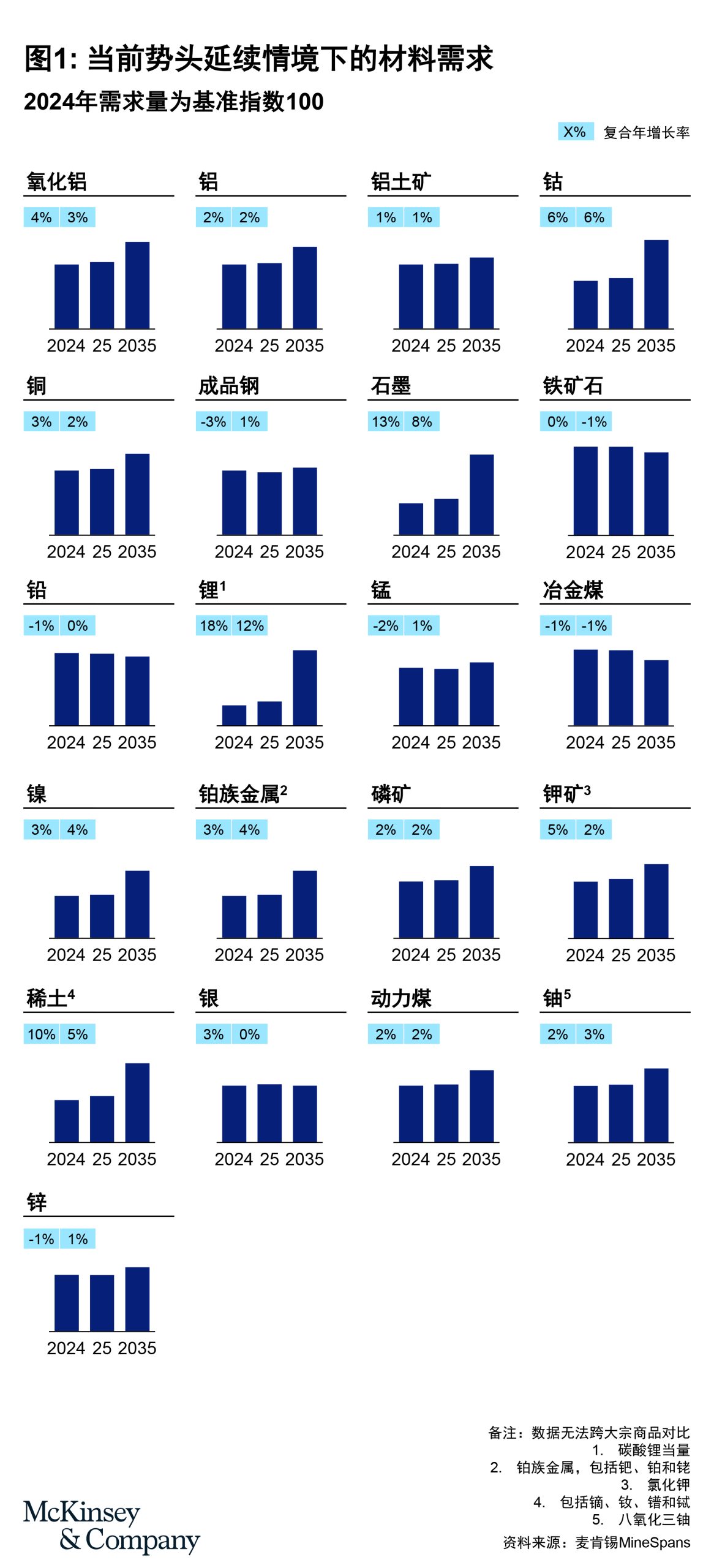
数据:智能体的根基
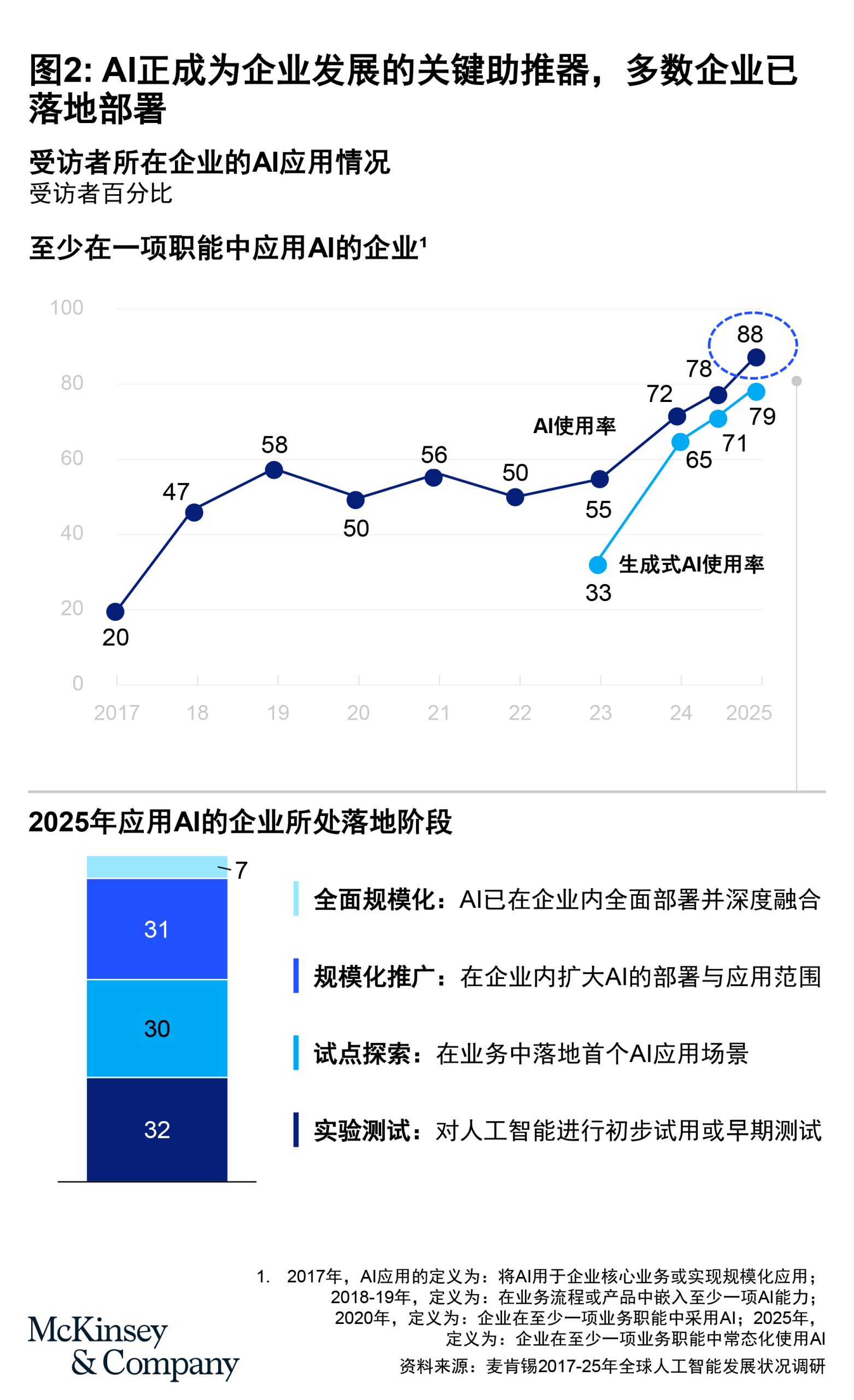
不少企业已将AI融入日常运营(见图2)。如今,它们正迈向下一程:引入智能体,推动复杂业务流程自动化。而智能体的稳定和规模化运行,离不开源源不断的高质量数据供给。
智能体的成功,仰赖于一套能够支撑更高自主性、协同能力与实时决策的数据架构。成熟架构往往采用模块化、可互通的设计框架,让智能体能够安全、可靠地获取所需数据(详见边栏“支撑规模化落地的七大数据架构原则”)。生成式AI已凸显出数据权限管控、溯源与全链路追踪的重要性,而智能体平台对这些基础能力提出了更高要求。由于智能体需要持续协调多个模型和数据源,且往往在无人干预下自主运行,治理机制必须更严密、更自动化,才能确保大规模运行时的可靠与可控。
目前主要有两类智能体形态:一是单智能体工作流,由单个智能体依次调用多种工具与数据源;二是多智能体工作流,由多个专业智能体通过共享知识图谱与细粒度数据权限开展协作。两类场景均依赖统一、可互通的数据底座,否则智能体就可能出现问题。单智能体可能因数据碎片化做出前后矛盾的决策,多智能体系统则可能丧失协同,并导致错误扩散。
为智能体准备好数据
要推动规模化转型,打造智能体型组织,企业首先要夯实底层数据能力。这既是技术焕新,也是组织变革。因为数据战略与运营模式,与底层数据质量与架构同等重要。企业需协同推进以下四个相互关联的步骤,打通战略、技术与人的维度:
- 第一步:筛选值得“智能体化”的高价值工作流。聚焦少数高价值的端到端工作流,通过提升自主性来释放价值。可借鉴数据产品方法论,依据价值潜力、可行性与战略契合度,优先推进若干智能体用例,再逐步扩大规模。
- 第二步:为智能体分层升级数据架构。无需全盘推倒重来,可在现有平台上进行现代化改造,实现跨系统的互操作与治理贯通。尽管有人可能寄望借AI弯道超车,绕过数据架构的最佳实践,但最优秀的组织往往会构建模块化、可演进的架构,让各组件能伴随新技术的出现灵活替换。
- 第三步:完善数据质量管控体系。从周期性的数据清理转向持续、实时的质量管理。并确保结构化与非结构化数据,以及智能体生成内容,均满足一致的准确性、可溯源性及治理标准。
- 第四步:搭建适配智能体的运营与治理体系。规模化部署智能体,意味着重新定义工作方式。人员角色随之转变,从具体执行,转向对智能体工作流的监督与统筹调度。在人机混合的工作环境中,必须建立清晰的治理规则,方能让智能体在规模化部署下安全透明地运行。
下文将逐一阐释这四个步骤。
筛选值得“智能体化”的高价值工作流
对大多数企业而言,通向智能体价值的合理路径不是“一次性重构一切”,而是在高价值领域有选择地对少数关键工作流进行“定向重构”(见图3)。领先者通常从知识管理、市场营销等关键领域入手,基于现有数据找准高价值场景,判断在哪些节点提升自主性,能对业务结果带来实质改善。路径上,先把端到端流程过一遍,再逐一圈定可由智能体增值的环节及所需的数据支撑。由此,便可按价值潜力与可行性为用例排定先后。

以明确指标为导向的针对性试点,可迅速验证早期成效。与此同时,团队需盘点可在不同任务、不同流程间复用的数据资产。复用思维,是走向规模化的关键。
为智能体分层升级数据架构
要让数据架构适配智能体,需要对数据技术栈逐层加固与调优。无需推倒重来,企业可在既有平台之上实施分层现代化改造,提升跨流程的数据可见性与治理贯通。
要直观理解现代化数据架构,可参考典型的全渠道零售旅程的例子。过去,商品数据与购买记录散落在各个孤岛系统中,客户一旦跨渠道,上下文便容易断裂,导致推荐与服务体验前后不一。面向智能体的架构要打通系统与数据链路,覆盖完整的消费旅程;并通过传统机器学习、生成式AI与智能体技术的协同,逐步实现全域数据互通。
在全渠道示例中,数据源层负责将客户浏览、心愿单、购买历史、客服互动等数据引入企业系统。非结构化数据在流入模型的过程中会被持续摄取、转换与重组,因此治理必须全程伴随。数据质量检查、安全管控和溯源追踪需自动化并直接嵌入数据管道,而非事后一次性审核。数据团队还要构建预处理流水线,完成数据清洗、信息增补与标注工作,补齐业务语境并嵌入质量校验,使智能体能够准确解读信息并稳定执行操作。
数据平台层负责贯通不同系统的数据,通过统一调度权限、状态同步与跨系统的实时交互,向各类应用与AI模型提供可用数据。在全渠道场景下,该层级确保当不同智能体跨渠道工作时,始终可以按需调用客户偏好、交互记录与交易状态等数据。
向量存储与嵌入服务是处理非结构化数据的基础能力,必须纳入数据平台体系。由此,我们可基于语义而非简单关键词,实现对文档、图像等非结构化内容的智能检索,并能随内容迭代及时更新语义表征。
在这一层叠加智能体专属的互通标准2,可实现集成与访问的自动化,支持结构化上下文共享、智能体间的直接协同以及安全的交易交互。例如,多智能体协作时,可在库存、履约、客户关系管理与支付等系统间实时检索并更新数据,在不丢失业务连续性的前提下完成协同操作。
在这一层级,智能体可维护专属的工作记忆或限定范围的上下文;而对共享数据与上下文的访问,则依据具体用例与权限实现动态治理。随着智能体自主性提升,身份与权限管理愈发关键,以保障数据质量、一致性与可审计性。
语义层则将数据转化为真正的知识。它介于原始数据与AI应用之间,把数据的业务含义编码成机器可读、人类可理解的形式。它不再将数据视为彼此割裂的表单或文件,而是定义其实际属性、关联关系与适用规范。
实际落地中,语义层大多以本体库与知识图谱为基础构建。本体库界定数据属性与数据关系如何共同映射业务现实;知识图谱则基于这套话语体系,打通各系统的真实业务数据,构建相互关联的实体网络。若缺乏统一的语义基础,智能体可能会对同一数据产生片面或矛盾的解读,随着规模扩大,错误率与运营风险都会走高。
数据产品把经过治理沉淀的数据,封装为可复用、标准化的业务资产。它们为数据明确界定所有权、质量门槛、语义定义与消费接口。秉持产品化思维,企业把数据当作可跨用例、跨领域复用的核心资产。可复用的数据产品,使智能体能够大规模汲取可信的预测式与生成式洞见;同时凭借可观测性记录智能体的数据使用轨迹,提供监管所需的可追溯性,并构建反馈闭环,持续优化上游数据与模型。
数据消费层位于整个技术栈的顶端,负责将数据与智能注入业务流程与应用中。它涵盖分析报表工具、数据API、检索接口,以及直接嵌入业务流程的模型输出。智能体编排与检索服务也部署在这一层。AI系统往往从非结构化数据中动态组织上下文,而非依赖预设查询。编排机制让AI自主决定检索什么、如何优化及何时迭代;检索服务则保障全过程的安全、高效与规模化治理。
现代架构还会分析模型输出,以反哺和强化数据本身。生成式AI应用可以生成标签、使用模式与上下文,用于提升数据质量并支撑后续模型迭代;这些输出与其他数据一样,也应被采集用于训练。
治理与权限管控是关键底座,用以规范智能体与数据、工具、模型的交互方式,确保在可控边界内运行。分层治理架构可将原始数据逐级打磨为适配智能体的形态,同时保留溯源链路与可审计性;其后通过API、查询与权限实施访问治理。鉴于模型会动态检索和使用非结构化数据,企业需部署AI网关统一管控访问与使用。该网关既要约束模型对非结构化数据的访问、强制执行使用策略,也要完整记录数据在指令输入与结果输出中的检索与使用情况。
筑牢数据质量体系
经过治理沉淀的高质量数据,已成为智能体时代企业的战略优势。部署基础大模型成本高昂,大规模推理、模型微调、基础设施建设和治理等环节均需投入高额费用。具备规整内部数据集的组织,可以依托自有数据对垂直领域的小模型进行微调,从而降低技术投入。这类模型不仅更省成本与算力,也更稳健、更易合规。
要盘活非结构化数据,需通过标签标注、分类整理、向量嵌入及图谱结构化处理等方式,系统提升数据质量,让智能体能够稳定理解实体、关系与上下文。非结构化数据应与结构化数据遵循同等严格的标准。
企业还需升级对结构化数据的管理方式,从过去的定期清理转向持续、实时的质量监控。这可借助AI驱动的自动校验、异常检测与数据增补流水线实现,有效阻断问题在工作流中的扩散。元数据管理则完整留存数据溯源链路与业务上下文,便于智能体追溯与解释其决策依据。
最后,随着智能体不断生成新数据,企业必须对其输出施以同样的质量、溯源和一致性标准。这包括智能体通过工具和API读取或写入的数据,这些操作都应通过受治理、可对账的标准化接口进行,不得绕过企业的质量管控体系。将统一且适配具体业务场景的定义标准嵌入到自动化质检流程中,可确保智能体在规模化运行时,始终基于可靠信息行事。
搭建面向智能体的运营与治理体系
随着智能体系统走向规模化,治理将成为首要的管控手段。企业需要制定清晰、具体的政策,界定智能体能做什么、能访问哪些数据、何时必须寻求人工审批,并依据每个智能体的角色与权限范围自动执行访问校验。尤为重要的是,智能体不应另起炉灶制定新的数据质量或治理规则,必须与企业既有标准完全对齐,并在自主性提升时自动、严格地加以执行。
成熟的智能体也能反哺治理:治理型智能体可在明确定义的控制框架内,持续监测其他智能体的行为,确保系统运行透明、合规。比如,创意合规智能体可审查图像与多媒体输出,识别品牌形象误用或政策违规,并及时触发纠偏措施。
IT与治理团队还需统一管理智能体全生命周期:发放身份凭证、追踪活动日志、监控运行表现,并通过自动化校验确保政策合规。依托内置遥测能力自动采集智能体活动数据,完整记录操作、数据访问与决策轨迹,实现全流程可追溯。
明确智能体行为的权责归属对于规模化部署至关重要,这涵盖业务结果、风险管理与政策合规等维度。实践中,各业务线负责智能体工作流的日常治理,包括领域模型与本体库的维护;中央数据与AI团队则负责共享平台、防护机制与全局监管。这种联邦式治理既保留了业务部门的自主性,又保障了企业层面的统一问责。
在智能体时代,底层数据能力正日益决定企业的竞争位置。尽管依托数据释放智能体价值的前景可期,许多企业仍难以搭建既便于智能体调用、又可合规治理的数据底座。如今,企业应把握这个推动数据变革的窗口期,为迈向智能体未来打好地基。
注释:
1 “Seizing the agentic AI advantage,”麦肯锡,2025年6月13日。
2 此类互通标准包括:模型上下文协议(MCP),用于规范智能体访问和共享上下文的方式;智能体间(A2A)通信框架,用于实现智能体之间的直接协同;以及智能体支付协议(AP2),用于支持可信的交易交互。
本文核心内容基于《麦肯锡讲全球企业数字化(第二版)》(Rewired: How Leading Companies Win with Technology and AI ,威立出版社,2026年4月14日,作者Eric Lamarre、Kate Smaje、Rob Levin、Alex Singla及Alexander Sukharevsky)中“没有数据架构,就没有AI优势”一章。
关于作者
Asin Tavakoli 是麦肯锡全球董事合伙人,常驻杜塞尔多夫分公司;Brian Goodman是麦肯锡全球董事合伙人,常驻纽约分公司;Kayvaun Rowshankish是麦肯锡全球资深董事合伙人,常驻纽约分公司;Akshat Kumar是麦肯锡全球副董事合伙人,常驻纽约分公司;Henning Soller是麦肯锡全球董事合伙人,常驻法兰克福分公司;Carlos Barreto是麦肯锡杰出数据工程师,常驻圣保罗分公司;Satyajit Parekh是麦肯锡资深知识专家,常驻波士顿分公司;Tancredi Bernard Litta Modignani是麦肯锡知识专家,常驻里斯本分公司。
作者感谢Artur Freitas Gonçalves、Francesco Scorca和徐雷对本文的贡献。



